Best Practice
This document aims to explain the best practices for integrating new models into the Konfig library and designing, building and writing KCL code models. New models are generally designed and abstracted using the best practice of separating front-end and back-end models. The direct purpose of distinguishing between front-end and back-end models is to separate "user interface" and "model implementation", achieving a user-friendly and simple configuration interface as well as automated configuration query and modification interfaces.
Workflow
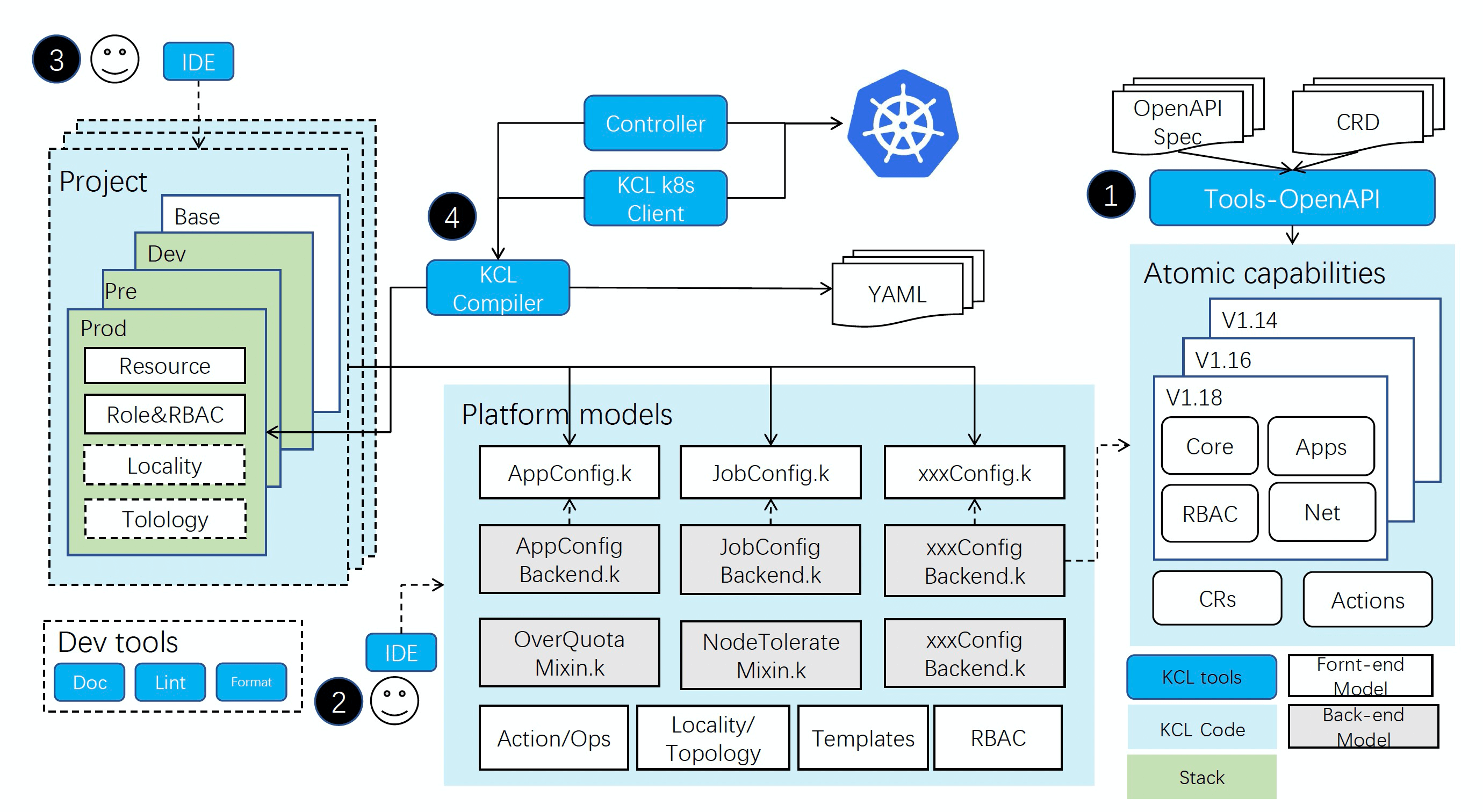
- Coding. Use the KCL OpenAPI tool to generate KCL schemas from the Customer Resources Definitions (CRDs) or OpenAPI Swagger models. These schemas define the atomic capabilities of the platform.
- Abstraction. Based on these atomic capabilities, the platform abstracts user-oriented front-end models and provides a set of templates. These front- end models cannot work independently, and corresponding back-end models are required. These back-end models will eventually obtain an instance of the front-end model at runtime; it parses the input front-end model and converts it into Kubernetes resources.
- Configuration. Developers or SREs describe the requirements of applications based on front-end models. Users can define the base and different environment configurations for different environments e.g., base, development and production and different localities. In most cases, defining configurations only requires declaring key-value pairs. For some complex scenarios, users can define the logic to generate configurations.
- Automation. After defining the user's configuration, all components have been defined and are ready to be automated. The platform can compile, execute, output, modify, query, and perform other automatic works through the KCL CLI or GPL-binding APIs. Users can also deploy the KCL configuration to the Kubernetes cluster with tools.
Model Structure
Just as web applications provide a friendly user interface, and user input is further inferred at the backend of the application to obtain the final data that falls into the database, similarly, using KCL for model design also follows the logic of front-end and back-end separation. In addition, when the downstream required data content changes, we only need to modify the rendering/logic of the user configuration data to the backend model, thereby avoiding large-scale modification of user configurations.
Taking the sidecar configuration of application services as an example:
# Config user interface.
user_sidecar_feature_gates: str
# Downstream config of processing.
sidecars = [
{
name = "sidecar_name" # Additional template for sidecars parameters, users do not need to configure them.
feature_gates = user_sidecar_feature_gates
}
]
Best Practices for Konfig Modeling
Use Single Attribute Instead of Configuration Templates
For some backend models, the configuration attributes that need to be filled in are often large and comprehensive designs, requiring users to actively input more complex configuration templates, and the filling content of this attribute is basically the same for different users. For example, the configuration of logic shown below requires users to fill in a large amount of template data, which has a high mental cost.
A simple best practice is to abstract such commonly used and complex templates into a simple attribute overQuota with the bool type in the front-end model, allowing users to do multiple-choice questions instead of filling in blank questions. For example, when the overQuota attribute is True, the back-end model will render this complex logic.
- The front-end attribute
overQuota
overQuota: bool
- The back-end YAML output:
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: k8s/is-over-quota
operator: In
values:
- 'true'
In addition, different template names can be designed according to specific business scenarios to fill in the blanks, such as designing an attribute template in the code shown below to assist users in template selection instead of directly filling in the template content. The legal template value can be "success_ratio" or "service_cost". When the backend model extends more templates, the front-end code does not need to make any modifications, only needs to adapt the corresponding template logic in the backend model.
schema SLI:
template: str = "success_ratio"
In addition, it is recommended to avoid using complex structures directly as front-end model attributes to avoid users needing to rely on too many KCL syntax features (such as unpacking, looping, etc.) or writing many temporary variables to complete the instantiation of the structure when using the model.
Use Literal Type and Union Type
In the above section, it was mentioned that a string attribute can be used to represent different template names, and further, a literal type can be used to express the optional content of the template. For example, the following improvements can be made.
schema SLI:
template: "success_ratio" | "service_cost" = "success_ratio"
The type of template is a combination of two string types, indicating that the template can only be "success_ratio" or "service_cost". When the user fills in the values of other strings, the KCL compiler will report an error.
In addition to using union types for literal types, KCL also supports union for complex types such as schema types. For the support of this backend oneof configuration, KCL has built-in composite structure union types for support. For example, we can define our own SLI front-end types for various scenarios: CustomSliDataSource, PQLSLIDataSource, and StackSLIDataSource.
schema CustomSLIDataSource:
customPluginUrl: str
schema PQLSLIDataSource:
total?: str
error?: str
success?: str
cost?: str
count?: str
schema StackSLIDataSource:
stack: str
groupBy?: str
metric?: str
# Simplify type definitions using type aliases
type DataSource = CustomSLIDataSource | PQLSLIDataSource | StackSLIDataSource
schema DataConfiguration:
sources: {str: DataSource}
The advantage of designing this front-end model is that the compiler can statically check that the type written by the user can only be a certain type. If the back-end model is used directly, it cannot directly obtain the mapping relationship between different types of types and the fields that need to be filled in from the model.
In addition, the overall design of the front-end model should also consider horizontal scalability, using the union type as much as possible, fully utilizing the advantages of coding, and avoiding unnecessary large amounts of code restructuring and modification when connecting to different backend or backend models. In addition, for the factory pattern commonly used in other GPL languages, union types can also be used instead in KCL. For example, if you want to obtain a constructor of a type based on the content of a string, you can directly use union types for optimization.
Using the factory pattern in KCL:
schema DataA:
id?: int = 1
value?: str = "value"
schema DataB:
name?: str = "DataB"
_dataFactory: {str:} = {
DataA = DataA
DataB = DataB
}
dataA = _dataFactory["DataA"]()
dataB = _dataFactory["DataB"]()
Replacing the factory pattern with the KCL union type.
schema DataA:
id?: int = 1
value?: str = "value"
schema DataB:
name?: str = "DataB"
# Just use the union type.
dataA: DataA | DataB = DataA()
dataB: DataA | DataB = DataB()
Use Dict Instead of List As Much As Possible
To make it easier to modify configurations on-site or automate queries, it is advisable to define list or array attributes as dictionary types for easy indexing. In many complex configuration scenarios, the index of a list is arbitrary and the order of elements has no impact on the configuration. Using a dictionary type instead of a list type allows for more convenient data querying and modification. For example:
schema Person:
name: str
age: int
schema House:
persons: [Person]
house = House {
persons = [
Person {
name = "Alice"
age = 18
}
Person {
name = "Bob"
age = 10
}
]
}
For example, in the above example, if you want to query the age of the person named "Alice" from the list of persons in the house, you need to loop through the list to find Alice's age. However, if you define persons as a dictionary like the following code, it not only looks more concise in code, but you can also directly retrieve Alice's age by using house.persons.Alice.age. In addition, the information of the entire configuration is complete and has no redundant information.
schema Person:
age: int
schema House:
persons: {str: Person} # Use Dict Instead of List
house = House {
persons = {
Alice = Person { age = 18 }
Bob = Person { age = 10 }
}
}
Write Validation Expressions for Models
For frontend models, it is often necessary to validate the fields filled in by users. In this case, KCL's check expressions can be used in conjunction with KCL's built-in functions/syntax/system libraries to perform field validation. For frontend model validation, it is recommended to directly write it in the frontend model definition as a prerequisite for validation, in order to avoid unexpected errors that may occur when the errors are passed to the backend model.
Use all/any expressions and check expressions for validation
import regex
schema ConfigMap:
name: str
data: {str:str}
configMounts?: [ConfigMount]
check:
all k in data {
regex.match(k, r"[A-Za-z0-9_.-]*")
}, "a valid config key must consist of alphanumeric characters, '-', '_' or '.'"
schema ConfigMount:
containerName: str
mountPath: str
subPath?: str
check:
":" not in mountPath, "mount path must not contain ':'"
Use Numerical Unit Type
Numbers with units in KCL have a built-in type of units.NumberMultiplier, and any arithmetic operations are not allowed.
import units
type NumberMultiplier = units.NumberMultiplier
x0: NumberMultiplier = 1M # Ok
x1: NumberMultiplier = x0 # Ok
x2 = x0 + x1 # Error: unsupported operand type(s) for +: 'number_multiplier(1M)' and 'number_multiplier(1M)'
We can use the int()/float() function and str() function to convert the number unit type to integer or string type, and the resulting string retains the units of the original number unit type.
a: int = int(1Ki) # 1024
b: str = str(1Mi) # "1Mi"
The definitions related to Kubernetes Resource in Konfig can be written using numerical unit types
import units
type NumberMultiplier = units.NumberMultiplier
schema Resource:
cpu?: NumberMultiplier | int = 1
memory?: NumberMultiplier = 1024Mi
disk?: NumberMultiplier = 10Gi
epchygontee?: int
Automated Modification of Front-end Model Instances
In KCL, automated modification of front-end model instances can be achieved through the CLI and API. For example, if we want to modify the image content of an application (Konfig Stack Path: apps/nginx example/dev) configuration, we can directly execute the following command to modify the image content.
kcl -Y kcl.yaml ci-test/settings.yaml -o ci-test/stdout.golden.yaml -d -O :appConfiguration.image=\"test-image-v1\"
For more documentation related to automation, please refer to the Automation Documents section.
Use Functions
# Define a function that adds two numbers and returns the result。
add = lambda x, y {
x + y
}
# Define a function that subs two numbers and returns the result。
sub = lambda x, y {
x - y
}
# Call the function, pass in arguments, and obtain the return value.
result = sub(add(2, 3), 2) # The result is 3.
The output YAML is
result: 3
Use Package and Module
Create a package called utils.k, define a KCL function called add in it, and import it into another file for use.
utils.k
# utils.k
# Define a function that adds two numbers and returns the result。
add = lambda x, y {
x + y
}
# Define a function that subs two numbers and returns the result。
sub = lambda x, y {
x - y
}
main.k
# main.k
import .utils
# Call the function, pass in arguments, and obtain the return value.
result = utils.sub(utils.add(2, 3), 2) # The result is 3.
Simplify Logical Expressions Using Configuration
# Complex Logic, `_cpu` is a non-exported and mutable attribute.
_cpu = 256
_priority = "1"
if _priority == "1":
_cpu = 256
elif _priority == "2":
_cpu = 512
elif _priority == "3":
_cpu = 1024
else:
_cpu = 2048
# Simplify Logic Expression using Config
cpuMap = {
"1" = 256
"2" = 512
"3" = 1024
}
# Get cpu from the cpuMap, when not found, use the default value 2048.
cpu = cpuMap[_priority] or 2048
The output is
cpuMap:
"1": 256
"2": 512
"3": 1024
cpu256: 256
cpu2048: 2048
Separate Logic and Data
We can use KCL schema, config, and lambda to separate data and logic as much as possible.
For example, we can write the following code (main.k).
schema Student:
"""Define a `Student` schema model with documents.
Attributes
----------
name : str, required
The name of the student.
id : int, required.
The id number of the student.
grade : int, required.
The grade of the student.
Examples
--------
s = Student {
name = "Alice"
id = 1
grade = 80
}
"""
name: str
id: int
grade: int
# Define constraints for the `Student` model.
check:
id >= 0
0 <= grade <= 100
# Student data.
students: [Student] = [
{name = "Alice", id = 1, grade = 85}
{name = "Bob", id = 2, grade = 70}
{name = "Charlie", id = 3, grade = 90}
{name = "David", id = 4, grade = 80}
{name = "Eve", id = 5, grade = 95}
]
# Student logic.
query_student_where_name = lambda students: [Student], name: str {
# Query the first student where name is `name`
filter s in students {
s.name == name
}?[0]
}
alice = query_student_where_name(students, name="Alice")
bob = query_student_where_name(students, name="Bob")
The output is
students:
- name: Alice
id: 1
grade: 85
- name: Bob
id: 2
grade: 70
- name: Charlie
id: 3
grade: 90
- name: David
id: 4
grade: 80
- name: Eve
id: 5
grade: 95
alice:
name: Alice
id: 1
grade: 85
bob:
name: Bob
id: 2
grade: 70
Add Comments for Models
To facilitate user understanding and automatic model documentation generation, it is necessary to write comments for the defined model. The comment content usually includes an explanation of the model, an explanation of model fields, types, default values, usage examples, and more. For detailed KCL schema code commenting guidelines and automatic model documentation generation, please refer to the KCL Documentation Specification. Additionally, we can use the kcl-doc generate command to extract documentation from the user-specified file or directory and output it to the specified directory.
Backend Model
The backend model is an "implementation model," which mainly includes the logical code to map the frontend model to the backend model. After the frontend model is written, we can use the frontend model schema to create frontend model instances, and write the corresponding backend mapping/rendering code to convert these frontend instances into the backend model. By using KCL's multi-file compilation and Schema.instances() function, the frontend and backend code can be highly decoupled, so that users only need to focus on frontend configuration without being aware of the complex validation and logical code of the model.